add wiki page
parent
a075c03b77
commit
afbacf0590
171
Behind-u6a---Developer's-Notes-on-Implementing-Unlambda.md
Normal file
171
Behind-u6a---Developer's-Notes-on-Implementing-Unlambda.md
Normal file
|
|
@ -0,0 +1,171 @@
|
|||
## 1. Compiling Unlambda
|
||||
|
||||
With a simple hand-written LL(0) parser, Unlambda source code can be trivially parsed into AST, which takes the form of a full binary tree, having "apply" operators as internal nodes and primitive functions as leaf nodes.
|
||||
|
||||
The following image shows the AST parsed from a `cat` program (code: ```` ```s`d`@|i`ci ````):
|
||||
|
||||

|
||||
|
||||
### 1.1 Basic Compilation Rules
|
||||
|
||||
Execution of an Unlambda program is basically a combination of "eval" and "apply" operations. One of the primary goal of compilation is to eliminate "eval", as AST is a static structure and precedence of "apply" operations can be determined at compile-time. However, behavior of "apply" depends on the function and the argument, whose implementation detail should not interest the compiler, are left to the runtime system.
|
||||
|
||||
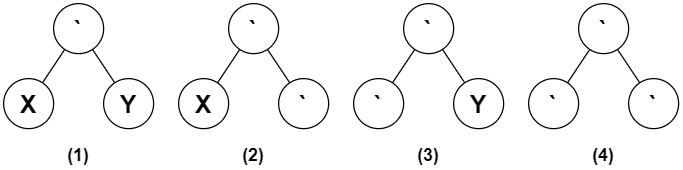
Within a single pre-order traversal, every internal node of Unlambda AST are compiled to 1 or 2 instructions, by following the rules depending on the types of its children, which are shown below (X, Y are primitive functions):
|
||||
|
||||
|
||||
|
||||
1. We just need to apply function X to Y. Compiles to `APP X, Y`. (See [\#2.2](#22-instruction-set) for instruction set details)
|
||||
2. Before X can be applied to its argument, the right child of this AST node has to be evaluated. Compiles to `NOP` (doing nothing), then push `APP X, acc` to a temporary compile-time stack.
|
||||
3. Before the left child of this AST can be applied to Y, it has to be evaluated to a function. Compiles to `NOP`, then push `APP acc, Y` to the stack.
|
||||
4. Compiles to `NOP`. Both child of this AST has to be evaluated. However, unlike (2), the compiler has no idea what function the left child evaluated to when the right child completes evaluation, so we push `SA` to the stack. Whenever an `SA` instruction is popped from the stack, an `LA` operation should be pushed to the stack.
|
||||
|
||||
After each (1), continuously pop instructions from the stack and append it to the list of compiled instructions, until one of the following conditions is met:
|
||||
|
||||
* An `SA` operation is just popped from the stack.
|
||||
* The stack is empty (which means the compilation is completed).
|
||||
|
||||
### 1.2 Function `d` and Promise
|
||||
|
||||
As you may have noticed, there's an obvious flaw in the said compilation rules - the special behaviour of function `d` wasn't taken into consideration. According to the Unlambda language specs, whenever an "operator" (the left child of an internal AST node) evaluates to function `d`, evaluation of the "operand" (its right sibling) is postponed and saved to a "promise", which may evaluate further in the future.
|
||||
|
||||
For rule (2), the compiler knows whether X is function `d`. When it is `d`, every instruction between the `NOP` and `APP d, acc` should be skipped, thus it compiles to `DEL offset`, where the "offset" points to the instruction next to the `APP d, acc`. The offset of the instruction next to `DEL offset` should be stored into the promise, so that the skipped instructions can execute in the future. Meanwhile, `APP d, acc` will never happen, so we change it into `AD` and introduce an internal function `f` ("finalize"), which applies the argument to the element popped from the stack, and restores the instruction pointed it saved. The function `f` is pushed to the runtime stack whenever the promise is applied to an argument, which should be pushed to the stack beforehand.
|
||||
|
||||
For rule (4), the left child may evaluate to `d`. If not, `SA` behaves normally (saves accumulator), otherwise, it behaves like `DEL`, which requires it to take an offset as operand as well.
|
||||
|
||||
Rules (1) and (3) are not affected, as there are no evaluations left to postpone, and `d` can be applied as a normal function.
|
||||
|
||||
The following image shows the compilation of the `cat` program mentioned above:
|
||||
|
||||

|
||||
|
||||
Note that an `APP e, acc` instruction is appended to the end of program as a guard to explicitly terminate the program upon end of execution.
|
||||
|
||||
### 1.3 Substituted Application
|
||||
|
||||
The ``` ``sXY ``` function differs from any existing Unlambda functions, for it's not applied to its argument directly. Instead, it performs a "substituted application". When ``` ``sXY ``` is applied to function Z, the evaluation result of ``` ``XZ`YZ ``` is returned. Extra evaluation means extra instructions have to be generated. A special code section for "substituted application" is shown below:
|
||||
|
||||
```text
|
||||
0x00: LA // `XZ -> U
|
||||
0x01: XCH
|
||||
0x02: LA // `YZ -> V
|
||||
0x03: LA // `UV
|
||||
0x04: LA
|
||||
```
|
||||
|
||||
When ``` ``sXY ``` is applied to an argument Z, we successively push function `j`, Z, Y and X into the runtime stack, and set the instruction pointer to the first line of the instructions above. Function `j` ("jump") is another internal function we introduced, which acts like `i`, with the side affect of restoring the instruction pointer it stores. Thus, execution can proceed to the main code section after substituted application is completed.
|
||||
|
||||
However, result of `` `XZ`` may be function `d`, which postpones the `` `YZ `` evaluation. The task of testing the value of U falls to `XCH`. Unlike the cases in [\#1.2](#12-function-d-and-promise), where the size of postponed instructions varies, here only 1 instruction can be skipped. Meanwhile, promise is created by popping two elements from the stack, rather than storing pointer to the line of instruction.
|
||||
|
||||
Another problem is when `` `XZ `` evaluates to another ``` ``sXY ``` function, it will be applied by the `LA` instruction at 0x03 (similar to a tail call). If done indefinitely, like in ```` ```sii``sii ````, the stack will be filled with `j` functions storing the address of 0x04 until memory is exhausted. Those `j` functions are meant to be consumed by the `LA` instruction at 0x04, but unfortunately, it exists outside the loop and never gets executed. TCO can be performed at runtime by checking the value of the instruction pointer when applying ``` ``sXY ```. If it equals to 0x03, do not push `j` into the stack.
|
||||
|
||||
### 1.4 Optimizations
|
||||
|
||||
Quite a few compile-time optimizations can be employed to improve runtime performance, which are not limited to the following examples.
|
||||
|
||||
#### 1.4.1 Constant Folding & Propagation
|
||||
|
||||
Certain Unlambda expressions have constant evaluation results, such as ``` ``kXY ``` (always yields X), and ``` `i`i`ii ``` (evaluates to `i`). These expressions can be recognized and evaluated at compile-time.
|
||||
|
||||
Another notable case is printing strings. In Unlambda, only one character can be printed per `.x` function call. To perform string printing, chaining of the `.x` function is required. For example, a program which prints "hello" ( `` `.o`.l`.l`.e`.hv `` ) compiles to:
|
||||
|
||||
```text
|
||||
0x00: APP .h, v
|
||||
0x01: APP .e, acc
|
||||
0x02: APP .l, acc
|
||||
0x03: APP .l, acc
|
||||
0x04: APP .o, acc
|
||||
```
|
||||
|
||||
By storing "hello" as a constant, and introducing a `p` ("print") internal function (which stores the pointer to the string constant and behaves like `i` with a side affect of printing the string), the instructions can be optimized to:
|
||||
|
||||
```text
|
||||
0x00: LC<print> 0x00 // Stores function p to accumulator
|
||||
0x01: APP acc, v
|
||||
```
|
||||
|
||||
#### 1.4.2 Dead Code Elimination
|
||||
|
||||
For an `APP` instruction with an immediate `e` as first operand:
|
||||
|
||||
* If it lies within a `DEL` or `SA` block, all instructions **after** this instruction and **before** the instruction referenced by `DEL` or `SA` are never reached and can be eliminated.
|
||||
* Otherwise, all instructions after it can be eliminated.
|
||||
|
||||
## 2. The Unlambda Virtual Machine
|
||||
|
||||
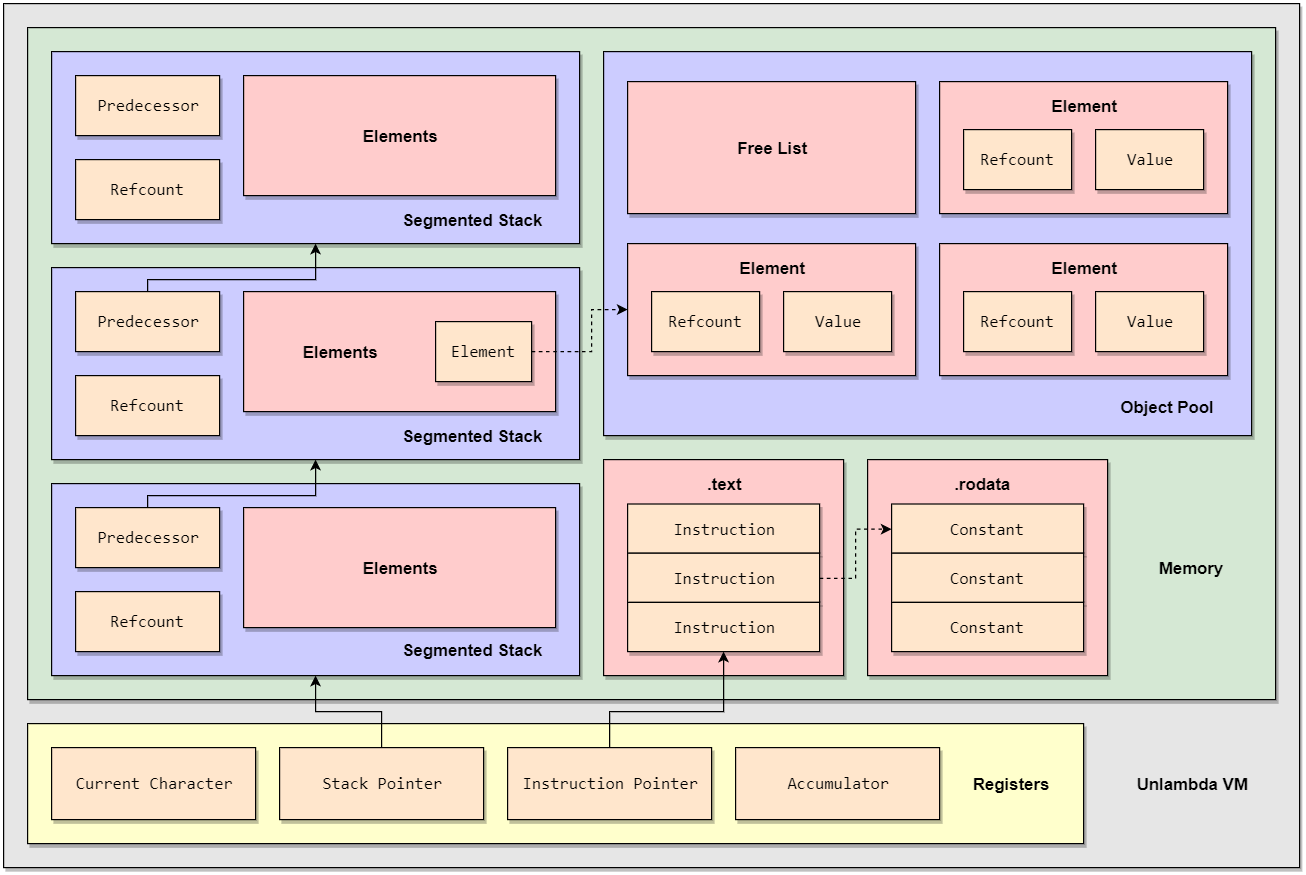
The Unlambda VM is a process virtual machine specially designed and optimized for the Unlambda programming language.
|
||||
|
||||
### 2.1 Architecture Overview
|
||||
|
||||
|
||||
|
||||
The Unlambda VM utilizes an accumulator-based architecture, having the "accumulator" as the general purpose register, while the other three registers being the instruction pointer, the stack pointer, and the "current character". The "current character" is an Unlambda-specific concept, which is used internally by some primitive I/O functions of Unlambda.
|
||||
|
||||
The ".text" and ".rodata" sections, which remain read-only at runtime, are loaded from bytecode file when VM initializes. Instructions are located to the ".text" section, and constants to the ".rodata" section. Although there's no such concept as a "constant" in the Unlambda language itself, there are a few compile-time optimization techniques where constants are required.
|
||||
|
||||
Dynamic memory allocation is required when `` `kX `` `` `sX `` ``` ``sXY ``` functions, promises or continuations are created, to store `X` `Y` and pointers. An object pool is introduced, due to inefficiency of frequent `malloc()`s and `free()`s of small, fixed-size blocks of memory. Objects in the pool are safely reference counted, for all of them are immutable by design, creating no reference cycles.
|
||||
|
||||
The Unlambda VM takes advantage of segmented stacks to lower the overhead of context-switching. During continuation capture and reinstatement, only the "active" stack segment (referenced by the stack pointer) need to be copied/freed, rather than the entire stack. Stack segments are reference counted to employ copy-on-write, and they can be pooled as well to alleviate potential performance degradation caused by the "hot split" issue.
|
||||
|
||||
### 2.2 Instruction Set
|
||||
|
||||
An Unlambda VM instruction consists of an opcode followed by 0 to 2 operands. There are a total of 6 different instructions, which are listed below.
|
||||
|
||||
| Mnemonic | Operands | Behavior |
|
||||
| --------------------------- | ----------------------------------------- | -------- |
|
||||
| `APP` <br>(Apply) | Function x2 <br>(immediate / accumulator) | Applies the first operand to the second one, and save the result to the accumulator. |
|
||||
| `LA` <br>(Load and Apply) | None | Pop the top element from the stack, and apply it to the value of the accumulator. The result is saved into the accumulator. |
|
||||
| `SA` <br>(Save Accumulator) | Address x1 <br>(immediate) | **If** the accumulator value is function `d`, create a promise which stores the current instruction pointer, save the promise to the accumulator, and set the instruction pointer to the operand value. <br>**If not**, Push the value of the accumulator to the stack. |
|
||||
| `DEL` <br>(Delay) | Address x1 <br>(immediate) | Create a promise which stores the current instruction pointer, save the promise to the accumulator, and set the instruction pointer to the operand value. |
|
||||
| `LC<?>` <br>(Load Constant) | Address x1 <br>(immediate) | Load constant from ".rodata" section starting from the address specified by the operand. This operation requires an "extended opcode" where the purpose of loaded constant is specified. Accumulator value is expected to change after this operation. |
|
||||
| \* `XCH` <br>(Exchange) | None | **If** the accumulator value is function `d`, pop two elements from the stack and create a promise to store them, then save the promise to the accumulator, finally, increment the instruction pointer by 2. <br>**If not**, swap the value between the accumulator and the element **next to** the stack top. |
|
||||
|
||||
\* Note: The `XCH` instruction is reserved for internal use only, and should never appear in bytecode files.
|
||||
|
||||
### 2.3 Bytecode File Format
|
||||
|
||||
Currently, the Unlambda bytecode file consists of 4 consecutive sections:
|
||||
|
||||
| Section | Description |
|
||||
| -------------- | -------------------------------- |
|
||||
| File header | Metadata of the bytecode file |
|
||||
| Program header | Metadata of the Unlambda program |
|
||||
| .text | Instructions |
|
||||
| .rodata | Compile-time constants |
|
||||
|
||||
File header:
|
||||
|
||||
| Offset | Size (bytes) | Content |
|
||||
| ------ | ------------ | ------------------------------ |
|
||||
| 0x00 | 1 | Magic number: `0xDC` |
|
||||
| 0x01 | 1 | Major version number |
|
||||
| 0x02 | 1 | Minor version number |
|
||||
| 0x03 | 1 | Size of program header (bytes) |
|
||||
|
||||
Program header:
|
||||
|
||||
| Offset | Size (bytes) | Content |
|
||||
| ------ | ------------ | --------------------------------- |
|
||||
| 0x00 | 4 | Size of ".text" section (bytes) |
|
||||
| 0x04 | 4 | Size of ".rodata" section (bytes) |
|
||||
|
||||
Instruction:
|
||||
|
||||
| Offset | Size (bytes) | Content |
|
||||
| ------ | ------------ | ------------------------------------------------------ |
|
||||
| 0x00 | 1 | Opcode |
|
||||
| 0x01 | 1 | Extended opcode |
|
||||
| 0x02 | 2 | Reserved |
|
||||
| 0x04 | 4 | Operand(s): <br>2x function **or** 1x address (32-bit) |
|
||||
|
||||
Function operand:
|
||||
|
||||
| Offset | Size (bytes) | Content |
|
||||
| ------ | ------------ | ------------------------------------------------- |
|
||||
| 0x00 | 1 | Function type |
|
||||
| 0x01 | 1 | ASCII character 'x' held by function `.x` or `?x` |
|
||||
|
||||
Notes:
|
||||
|
||||
* Anything before the magic number is omitted (allowing a shebang to be added).
|
||||
* Integers are of network byte order.
|
||||
* Anything after the last section is discarded.
|
||||
Loading…
Reference in New Issue
Block a user